Pandas para usuarios de Microsoft Excel — 19:50 min
19:50 min | Última modificación: Octubre 6, 2021
Preparación
[1]:
import numpy as np
import pandas as pd
Lectura de un archivo CSV
[2]:
url = 'https://raw.github.com/pandas-dev/pandas/master/pandas/tests/io/data/csv/tips.csv'
tips = pd.read_csv(url)
tips.head(n=5)
[2]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
Autofiltro en Microsoft Excel
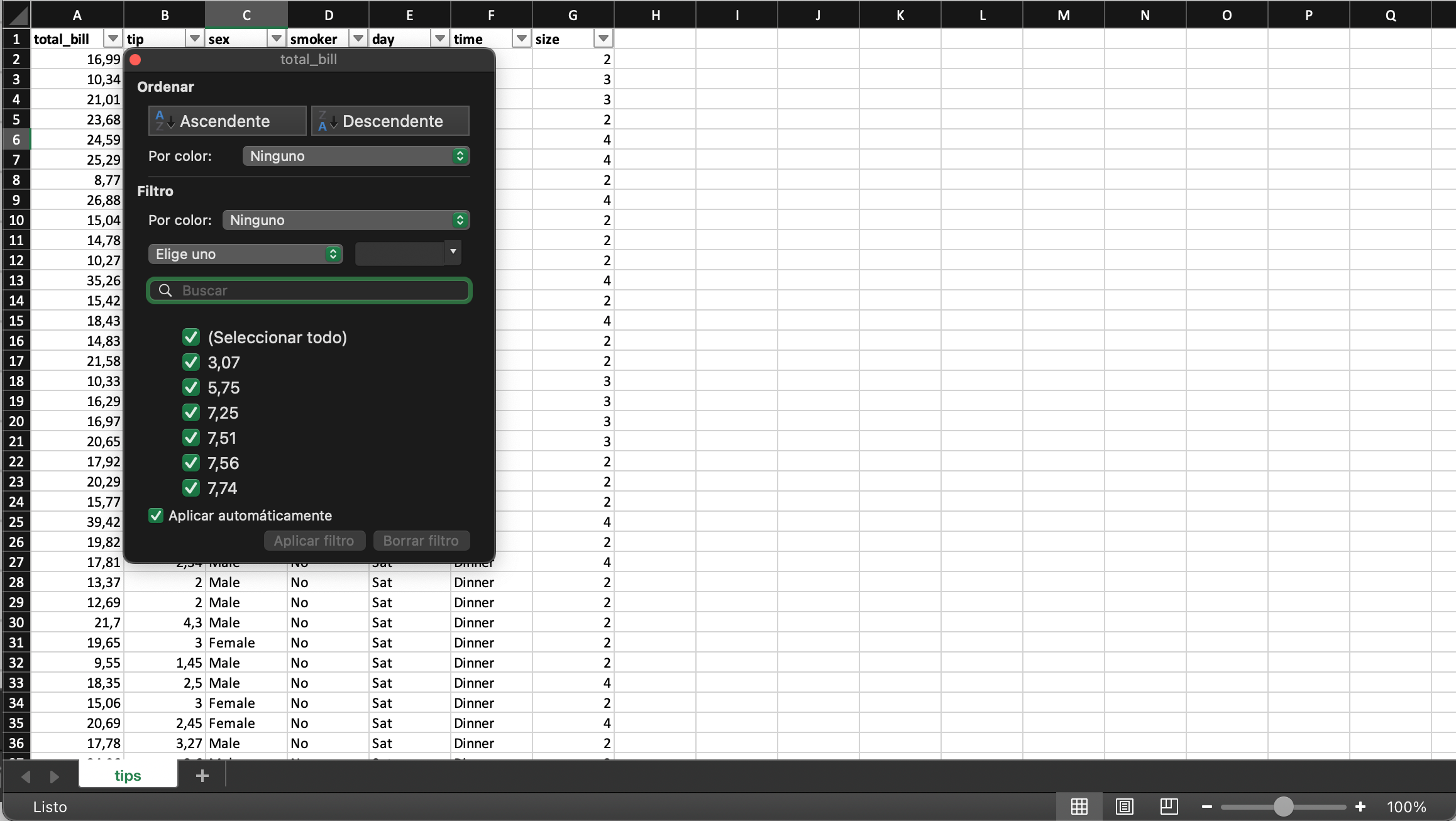
## Ordenamiento de una columna
[3]:
tips.sort_values(
by=["sex", "tip"],
ascending=[True, False],
).head(n=10)
[3]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 214 | 28.17 | 6.50 | Female | Yes | Sat | Dinner | 3 |
| 52 | 34.81 | 5.20 | Female | No | Sun | Dinner | 4 |
| 85 | 34.83 | 5.17 | Female | No | Thur | Lunch | 4 |
| 155 | 29.85 | 5.14 | Female | No | Sun | Dinner | 5 |
| 11 | 35.26 | 5.00 | Female | No | Sun | Dinner | 4 |
| 73 | 25.28 | 5.00 | Female | Yes | Sat | Dinner | 2 |
| 143 | 27.05 | 5.00 | Female | No | Thur | Lunch | 6 |
| 197 | 43.11 | 5.00 | Female | Yes | Thur | Lunch | 4 |
| 238 | 35.83 | 4.67 | Female | No | Sat | Dinner | 3 |
| 93 | 16.32 | 4.30 | Female | Yes | Fri | Dinner | 2 |
Filtrado
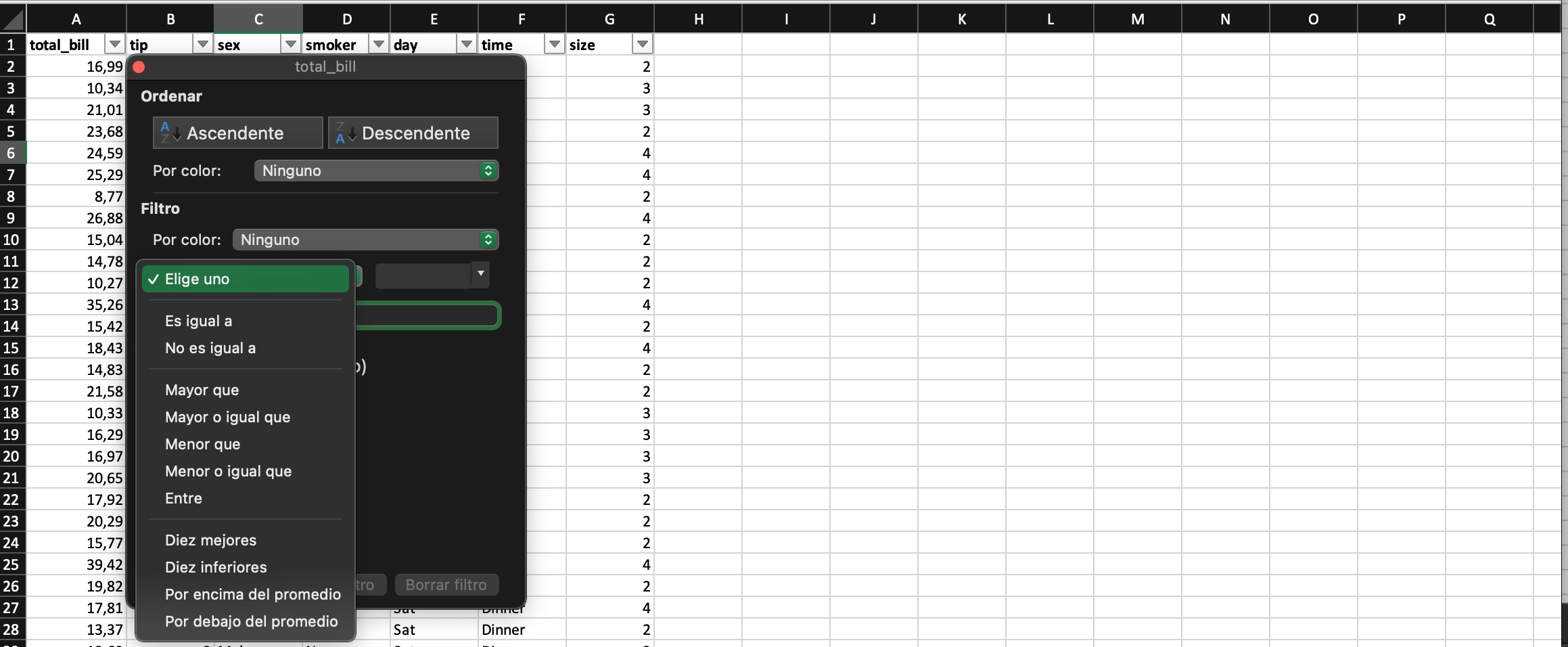
[4]:
#
# Filtro "Mayor que"
#
tips[tips['tip'] > 6.50].head(n=10)
[4]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 23 | 39.42 | 7.58 | Male | No | Sat | Dinner | 4 |
| 59 | 48.27 | 6.73 | Male | No | Sat | Dinner | 4 |
| 141 | 34.30 | 6.70 | Male | No | Thur | Lunch | 6 |
| 170 | 50.81 | 10.00 | Male | Yes | Sat | Dinner | 3 |
| 212 | 48.33 | 9.00 | Male | No | Sat | Dinner | 4 |
[5]:
#
# Comando equivalente con query
#
tips.query('tip > 6.50').head(n=10)
[5]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 23 | 39.42 | 7.58 | Male | No | Sat | Dinner | 4 |
| 59 | 48.27 | 6.73 | Male | No | Sat | Dinner | 4 |
| 141 | 34.30 | 6.70 | Male | No | Thur | Lunch | 6 |
| 170 | 50.81 | 10.00 | Male | Yes | Sat | Dinner | 3 |
| 212 | 48.33 | 9.00 | Male | No | Sat | Dinner | 4 |
[6]:
#
# Filtro con condicional compuesto
#
tips[(tips['tip'] > 6.50) & (tips['time'] == 'Dinner')].head(n=10)
[6]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 23 | 39.42 | 7.58 | Male | No | Sat | Dinner | 4 |
| 59 | 48.27 | 6.73 | Male | No | Sat | Dinner | 4 |
| 170 | 50.81 | 10.00 | Male | Yes | Sat | Dinner | 3 |
| 212 | 48.33 | 9.00 | Male | No | Sat | Dinner | 4 |
[7]:
#
# Filtro "Por encima del promedio"
#
tips[
tips['tip'] > tips['tip'].mean()
].tail(n=10)
[7]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 219 | 30.14 | 3.09 | Female | Yes | Sat | Dinner | 4 |
| 221 | 13.42 | 3.48 | Female | Yes | Fri | Lunch | 2 |
| 223 | 15.98 | 3.00 | Female | No | Fri | Lunch | 3 |
| 227 | 20.45 | 3.00 | Male | No | Sat | Dinner | 4 |
| 231 | 15.69 | 3.00 | Male | Yes | Sat | Dinner | 3 |
| 232 | 11.61 | 3.39 | Male | No | Sat | Dinner | 2 |
| 234 | 15.53 | 3.00 | Male | Yes | Sat | Dinner | 2 |
| 238 | 35.83 | 4.67 | Female | No | Sat | Dinner | 3 |
| 239 | 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 243 | 18.78 | 3.00 | Female | No | Thur | Dinner | 2 |
[8]:
#
# Cómputo del promedio
#
tips['tip'].mean()
[8]:
2.99827868852459
[9]:
#
# Diez mejores
#
tips.nlargest(10, 'tip')
[9]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 170 | 50.81 | 10.00 | Male | Yes | Sat | Dinner | 3 |
| 212 | 48.33 | 9.00 | Male | No | Sat | Dinner | 4 |
| 23 | 39.42 | 7.58 | Male | No | Sat | Dinner | 4 |
| 59 | 48.27 | 6.73 | Male | No | Sat | Dinner | 4 |
| 141 | 34.30 | 6.70 | Male | No | Thur | Lunch | 6 |
| 183 | 23.17 | 6.50 | Male | Yes | Sun | Dinner | 4 |
| 214 | 28.17 | 6.50 | Female | Yes | Sat | Dinner | 3 |
| 47 | 32.40 | 6.00 | Male | No | Sun | Dinner | 4 |
| 239 | 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 88 | 24.71 | 5.85 | Male | No | Thur | Lunch | 2 |
[10]:
#
# Diez inferiores
#
tips.nsmallest(10, 'tip')
[10]:
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 67 | 3.07 | 1.00 | Female | Yes | Sat | Dinner | 1 |
| 92 | 5.75 | 1.00 | Female | Yes | Fri | Dinner | 2 |
| 111 | 7.25 | 1.00 | Female | No | Sat | Dinner | 1 |
| 236 | 12.60 | 1.00 | Male | Yes | Sat | Dinner | 2 |
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 215 | 12.90 | 1.10 | Female | Yes | Sat | Dinner | 2 |
| 237 | 32.83 | 1.17 | Male | Yes | Sat | Dinner | 2 |
| 75 | 10.51 | 1.25 | Male | No | Sat | Dinner | 2 |
| 135 | 8.51 | 1.25 | Female | No | Thur | Lunch | 2 |
| 235 | 10.07 | 1.25 | Male | No | Sat | Dinner | 2 |
Eliminación de una columna
[11]:
tips.drop("day", axis=1)
[11]:
| total_bill | tip | sex | smoker | time | size | |
|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Dinner | 4 |
| ... | ... | ... | ... | ... | ... | ... |
| 239 | 29.03 | 5.92 | Male | No | Dinner | 3 |
| 240 | 27.18 | 2.00 | Female | Yes | Dinner | 2 |
| 241 | 22.67 | 2.00 | Male | Yes | Dinner | 2 |
| 242 | 17.82 | 1.75 | Male | No | Dinner | 2 |
| 243 | 18.78 | 3.00 | Female | No | Dinner | 2 |
244 rows × 6 columns
Cambio del nombre de una columna
[12]:
tips.rename(
columns={"smoker": "is_smoker"},
)
[12]:
| total_bill | tip | sex | is_smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 239 | 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 240 | 27.18 | 2.00 | Female | Yes | Sat | Dinner | 2 |
| 241 | 22.67 | 2.00 | Male | Yes | Sat | Dinner | 2 |
| 242 | 17.82 | 1.75 | Male | No | Sat | Dinner | 2 |
| 243 | 18.78 | 3.00 | Female | No | Thur | Dinner | 2 |
244 rows × 7 columns
Subtotales
[13]:
#
# Contar -- size()
#
tips.groupby('sex').size()
[13]:
sex
Female 87
Male 157
dtype: int64
[14]:
#
# Contar -- size() vs count()
#
tips.groupby('sex').count()
[14]:
| total_bill | tip | smoker | day | time | size | |
|---|---|---|---|---|---|---|
| sex | ||||||
| Female | 87 | 87 | 87 | 87 | 87 | 87 |
| Male | 157 | 157 | 157 | 157 | 157 | 157 |
[15]:
#
# Contar -- max(), min(), ...
#
tips.groupby('sex').max()
[15]:
| total_bill | tip | smoker | day | time | size | |
|---|---|---|---|---|---|---|
| sex | ||||||
| Female | 44.30 | 6.5 | Yes | Thur | Lunch | 6 |
| Male | 50.81 | 10.0 | Yes | Thur | Lunch | 6 |
[16]:
#
# Funciones diferenciales por columna
#
tips.groupby("sex").agg(
{
"tip": np.max,
"total_bill": np.mean,
}
)
[16]:
| tip | total_bill | |
|---|---|---|
| sex | ||
| Female | 6.5 | 18.056897 |
| Male | 10.0 | 20.744076 |
[17]:
tips.groupby(
"sex",
as_index=True,
).agg(
{
"tip": np.max,
"total_bill": np.mean,
}
)
[17]:
| tip | total_bill | |
|---|---|---|
| sex | ||
| Female | 6.5 | 18.056897 |
| Male | 10.0 | 20.744076 |
[18]:
#
# Opción as_index
#
tips.groupby(
"sex",
as_index=True,
).agg({"tip": np.max, "total_bill": np.mean})
[18]:
| tip | total_bill | |
|---|---|---|
| sex | ||
| Female | 6.5 | 18.056897 |
| Male | 10.0 | 20.744076 |
[19]:
tips.groupby(
"sex",
as_index=False,
).agg({"tip": np.max, "total_bill": np.mean})
[19]:
| sex | tip | total_bill | |
|---|---|---|---|
| 0 | Female | 6.5 | 18.056897 |
| 1 | Male | 10.0 | 20.744076 |
Computos sobre las columnas de una tabla
[20]:
tips.columns
[20]:
Index(['total_bill', 'tip', 'sex', 'smoker', 'day', 'time', 'size'], dtype='object')
[21]:
#
# Una nueva columna
#
tips.assign(tax10=0.1 * tips.total_bill)
[21]:
| total_bill | tip | sex | smoker | day | time | size | tax10 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 | 1.699 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 | 1.034 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 | 2.101 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 | 2.368 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 | 2.459 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 239 | 29.03 | 5.92 | Male | No | Sat | Dinner | 3 | 2.903 |
| 240 | 27.18 | 2.00 | Female | Yes | Sat | Dinner | 2 | 2.718 |
| 241 | 22.67 | 2.00 | Male | Yes | Sat | Dinner | 2 | 2.267 |
| 242 | 17.82 | 1.75 | Male | No | Sat | Dinner | 2 | 1.782 |
| 243 | 18.78 | 3.00 | Female | No | Thur | Dinner | 2 | 1.878 |
244 rows × 8 columns
[22]:
#
# Computos con valores respecto a otras filas
#
x = pd.DataFrame([10, 21, 32, 42, 55, 61, 74], columns=['Valores'])
x
[22]:
| Valores | |
|---|---|
| 0 | 10 |
| 1 | 21 |
| 2 | 32 |
| 3 | 42 |
| 4 | 55 |
| 5 | 61 |
| 6 | 74 |
[23]:
x.shift(periods=2, fill_value=0)
[23]:
| Valores | |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 2 | 10 |
| 3 | 21 |
| 4 | 32 |
| 5 | 42 |
| 6 | 55 |
[24]:
x.shift(periods=-2, fill_value=0)
[24]:
| Valores | |
|---|---|
| 0 | 32 |
| 1 | 42 |
| 2 | 55 |
| 3 | 61 |
| 4 | 74 |
| 5 | 0 |
| 6 | 0 |
Escenarios
[25]:
#
# Alternativa 1
#
escenarios = [
(1, 2, 3),
(4, 5, 6),
(7, 8, 9),
(10, 11, 12),
]
a, b, c = escenarios[1]
a + b + c
[25]:
15
[26]:
#
# Alterantiva 2
#
def f(a, b, c):
return a + b + c
escenarios = [
{"a": 1, "b": 2, "c": 3},
{"a": 4, "b": 5, "c": 6},
{"a": 7, "b": 8, "c": 9},
{"a": 10, "b": 11, "c": 12},
]
f(**escenarios[1])
[26]:
15
Tablas dinámicas
[27]:
#
# Del ejemplo anterior
#
def f(a, b, c):
return a + b + c
escenarios = [
{"a": 1, "b": 2, "c": 3},
{"a": 4, "b": 5, "c": 6},
{"a": 7, "b": 8, "c": 9},
{"a": 10, "b": 11, "c": 12},
]
z = pd.DataFrame(range(len(escenarios)), columns=['Escenario'])
z
[27]:
| Escenario | |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
[28]:
z['f'] = [f(**escenarios[i]) for i in z['Escenario']]
z
[28]:
| Escenario | f | |
|---|---|---|
| 0 | 0 | 6 |
| 1 | 1 | 15 |
| 2 | 2 | 24 |
| 3 | 3 | 33 |
Solver
[29]:
def f0(x):
return sum([i**2 for i in x])
# 1^2 + 2^2 + 3^2 = 14
f0([1, 2, 3])
[29]:
14
[30]:
from scipy.optimize import minimize
minimize(f0, x0=[1, 2, 3]).x
[30]:
array([-1.17452324e-08, -8.75678727e-09, -3.66353142e-09])
Styles
Basado en:
https://pandas.pydata.org/pandas-docs/stable/user_guide/style.html
[31]:
import numpy as np
np.random.seed(24)
df = pd.DataFrame({'A': np.linspace(1, 10, 10)})
df = pd.concat([df, pd.DataFrame(np.random.randn(10, 4), columns=list('BCDE'))],
axis=1)
df.iloc[3, 3] = np.nan
df.iloc[0, 2] = np.nan
df
[31]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.0 | 1.329212 | NaN | -0.316280 | -0.990810 |
| 1 | 2.0 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.0 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.0 | 0.961538 | 0.104011 | NaN | 0.850229 |
| 4 | 5.0 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.0 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.0 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.0 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.0 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.0 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[32]:
def color_negative_red(val):
color = 'red' if val < 0 else 'black'
return 'color: %s' % color
df.style.applymap(color_negative_red)
[32]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.000000 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.000000 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.000000 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.000000 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.000000 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[33]:
def highlight_max(s):
is_max = s == s.max()
return ['background-color: yellow' if v else '' for v in is_max]
df.style.apply(highlight_max)
[33]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.000000 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.000000 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.000000 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.000000 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.000000 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[34]:
df.style.\
applymap(color_negative_red).\
apply(highlight_max)
[34]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.000000 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.000000 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.000000 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.000000 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.000000 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[35]:
df.style.apply(highlight_max, subset=['B', 'C', 'D'])
[35]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.000000 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.000000 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.000000 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.000000 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.000000 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[36]:
df.style.applymap(color_negative_red, subset=pd.IndexSlice[2:5, ["B", "D"]])
[36]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.000000 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.000000 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.000000 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.000000 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.000000 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[37]:
df.style.format("{:.2%}")
[37]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 100.00% | 132.92% | nan% | -31.63% | -99.08% |
| 1 | 200.00% | -107.08% | -143.87% | 56.44% | 29.57% |
| 2 | 300.00% | -162.64% | 21.96% | 67.88% | 188.93% |
| 3 | 400.00% | 96.15% | 10.40% | nan% | 85.02% |
| 4 | 500.00% | 145.34% | 105.77% | 16.56% | 51.50% |
| 5 | 600.00% | -133.69% | 56.29% | 139.29% | -6.33% |
| 6 | 700.00% | 12.17% | 120.76% | -0.20% | 162.78% |
| 7 | 800.00% | 35.45% | 103.75% | -38.57% | 51.98% |
| 8 | 900.00% | 168.66% | -132.60% | 142.90% | -208.94% |
| 9 | 1000.00% | -12.98% | 63.15% | -58.65% | 29.07% |
[38]:
df.style.format({'B': "{:0<4.0f}", 'D': '{:+.2f}'})
[38]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1000 | nan | -0.32 | -0.990810 |
| 1 | 2.000000 | -100 | -1.438713 | +0.56 | 0.295722 |
| 2 | 3.000000 | -200 | 0.219565 | +0.68 | 1.889273 |
| 3 | 4.000000 | 1000 | 0.104011 | +nan | 0.850229 |
| 4 | 5.000000 | 1000 | 1.057737 | +0.17 | 0.515018 |
| 5 | 6.000000 | -100 | 0.562861 | +1.39 | -0.063328 |
| 6 | 7.000000 | 0000 | 1.207603 | -0.00 | 1.627796 |
| 7 | 8.000000 | 0000 | 1.037528 | -0.39 | 0.519818 |
| 8 | 9.000000 | 2000 | -1.325963 | +1.43 | -2.089354 |
| 9 | 10.000000 | -000 | 0.631523 | -0.59 | 0.290720 |
[39]:
df.style.format({"B": lambda x: "±{:.2f}".format(abs(x))})
[39]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | ±1.33 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | ±1.07 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | ±1.63 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | ±0.96 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | ±1.45 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.000000 | ±1.34 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.000000 | ±0.12 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.000000 | ±0.35 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.000000 | ±1.69 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.000000 | ±0.13 | 0.631523 | -0.586538 | 0.290720 |
[40]:
df.style.format("{:.2%}", na_rep="-")
[40]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 100.00% | 132.92% | - | -31.63% | -99.08% |
| 1 | 200.00% | -107.08% | -143.87% | 56.44% | 29.57% |
| 2 | 300.00% | -162.64% | 21.96% | 67.88% | 188.93% |
| 3 | 400.00% | 96.15% | 10.40% | - | 85.02% |
| 4 | 500.00% | 145.34% | 105.77% | 16.56% | 51.50% |
| 5 | 600.00% | -133.69% | 56.29% | 139.29% | -6.33% |
| 6 | 700.00% | 12.17% | 120.76% | -0.20% | 162.78% |
| 7 | 800.00% | 35.45% | 103.75% | -38.57% | 51.98% |
| 8 | 900.00% | 168.66% | -132.60% | 142.90% | -208.94% |
| 9 | 1000.00% | -12.98% | 63.15% | -58.65% | 29.07% |
[41]:
df.style.highlight_null(null_color='red')
[41]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.000000 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.000000 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.000000 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.000000 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.000000 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[42]:
import seaborn as sns
cm = sns.light_palette("green", as_cmap=True)
df.style.background_gradient(cmap=cm)
[42]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.000000 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.000000 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.000000 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.000000 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.000000 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[43]:
df.loc[:4].style.background_gradient(cmap='viridis')
[43]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
[44]:
df.style.highlight_max(axis=0)
[44]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.000000 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.000000 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.000000 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.000000 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.000000 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[45]:
df.style.bar(subset=['A', 'B'], color='#d65f5f')
[45]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.000000 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.000000 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.000000 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.000000 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.000000 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[46]:
df.style.bar(subset=['A', 'B'], align='mid', color=['#d65f5f', '#5fba7d'])
[46]:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 1 | 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 4 | 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 5 | 6.000000 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 6 | 7.000000 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 7 | 8.000000 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 8 | 9.000000 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 9 | 10.000000 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[47]:
df.style.hide_index()
[47]:
| A | B | C | D | E |
|---|---|---|---|---|
| 1.000000 | 1.329212 | nan | -0.316280 | -0.990810 |
| 2.000000 | -1.070816 | -1.438713 | 0.564417 | 0.295722 |
| 3.000000 | -1.626404 | 0.219565 | 0.678805 | 1.889273 |
| 4.000000 | 0.961538 | 0.104011 | nan | 0.850229 |
| 5.000000 | 1.453425 | 1.057737 | 0.165562 | 0.515018 |
| 6.000000 | -1.336936 | 0.562861 | 1.392855 | -0.063328 |
| 7.000000 | 0.121668 | 1.207603 | -0.002040 | 1.627796 |
| 8.000000 | 0.354493 | 1.037528 | -0.385684 | 0.519818 |
| 9.000000 | 1.686583 | -1.325963 | 1.428984 | -2.089354 |
| 10.000000 | -0.129820 | 0.631523 | -0.586538 | 0.290720 |
[48]:
df.style.hide_columns(['C','D'])
[48]:
| A | B | E | |
|---|---|---|---|
| 0 | 1.000000 | 1.329212 | -0.990810 |
| 1 | 2.000000 | -1.070816 | 0.295722 |
| 2 | 3.000000 | -1.626404 | 1.889273 |
| 3 | 4.000000 | 0.961538 | 0.850229 |
| 4 | 5.000000 | 1.453425 | 0.515018 |
| 5 | 6.000000 | -1.336936 | -0.063328 |
| 6 | 7.000000 | 0.121668 | 1.627796 |
| 7 | 8.000000 | 0.354493 | 0.519818 |
| 8 | 9.000000 | 1.686583 | -2.089354 |
| 9 | 10.000000 | -0.129820 | 0.290720 |