Concatenacióny fusión de dataframes (concat() y append()) — 11:16 min
11:16 min | Última modificación: Octubre 6, 2021
La función concat() permite la concatenación de dataframes y series a lo largo de un eje.
[1]:
import pandas as pd
pd.set_option("display.notebook_repr_html", False)
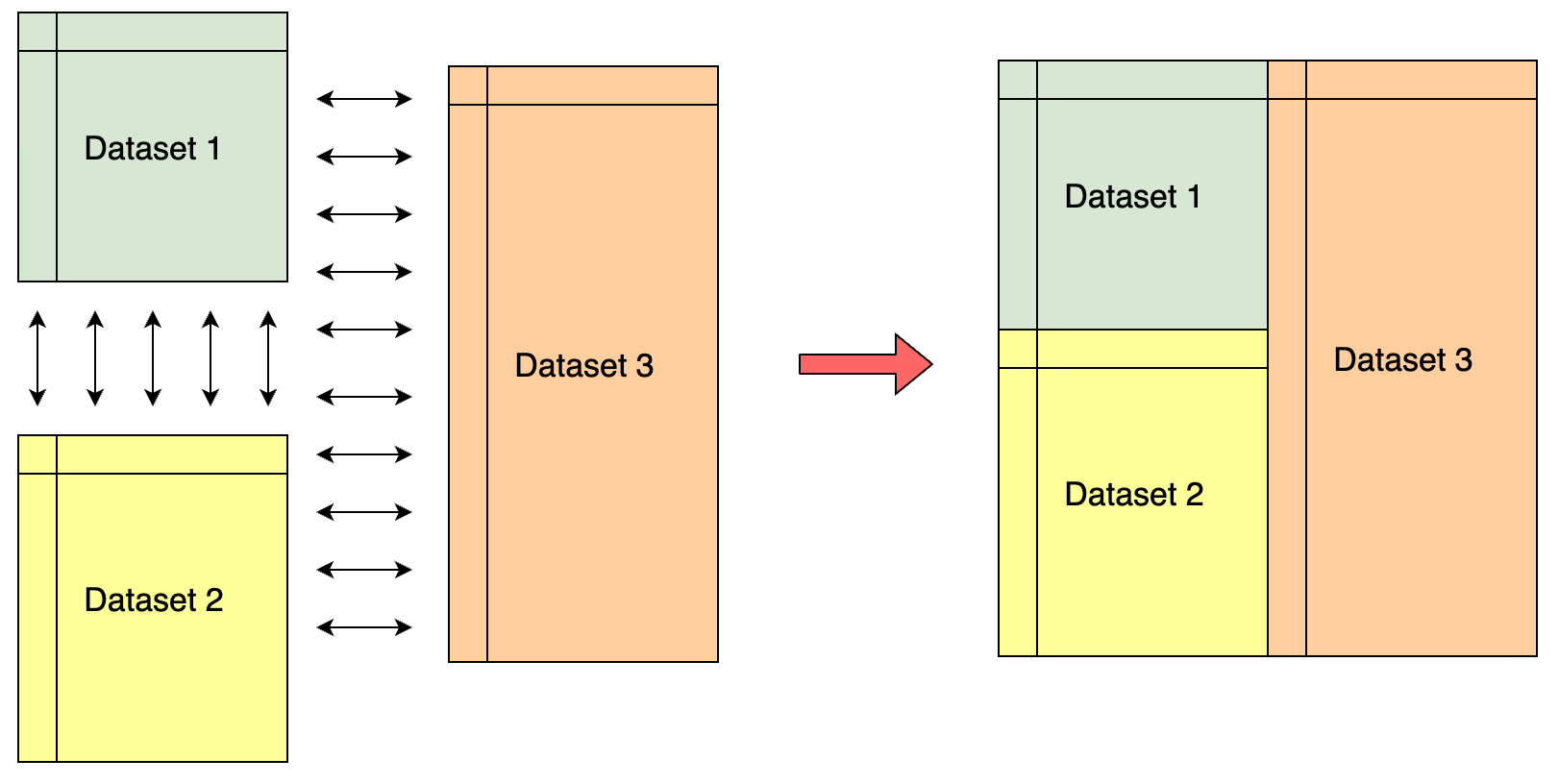
## Concatenación sin campos clave
Creación del dataframe 1
[2]:
%%writefile /tmp/dataset_1.csv
name,location
Omar Y. Fletcher,6833 Mollis. Rd.
Buffy W. Vincent,"P.O. Box 345, 8390 Ante Avenue"
Mira N. Franklin,"P.O. Box 445, 323 Cursus Rd."
Ferris Q. Le,Ap #791-3809 Eu Street
Michael I. Gray,6715 Diam. Rd.
Alan T. Mullins,512-3640 Nisl Rd.
Morgan W. Zamora,416-6030 Vivamus Road
Lilah O. Morrison,3859 Mauris Ave
Chantale Z. Kelley,3433 Arcu. Rd.
Randall Q. Mcclure,Ap #584-7470 Nibh. Ave
Writing /tmp/dataset_1.csv
Creación del dataframe 2
[3]:
%%writefile /tmp/dataset_2.csv
name,location
Baker C. Hurst,249-6250 Velit. Rd.
Bevis W. Molina,"P.O. Box 935, 1521 At, St."
Martina B. Schroeder,689-7600 Mi St.
Kylie G. Bailey,1430 Diam. Road
Steel K. Glover,"757-681 Et, Av."
Lucas M. Suarez,699-9329 Magna Rd.
Anastasia Q. Mccray,"P.O. Box 780, 4487 Lobortis, St."
Germaine Q. Henson,589-4921 Duis Ave
Wilma U. Mcfadden,6917 Dictum Rd.
Merritt Q. Martinez,"P.O. Box 469, 7833 Euismod Av."
Writing /tmp/dataset_2.csv
Creación del dataframe 3
[5]:
%%writefile /tmp/bonus.csv
bonus
279
138
227
160
267
231
169
263
233
292
208
247
240
161
248
216
291
215
463
790
Writing /tmp/bonus.csv
Concatenación de los dataframes 1 y 2
[6]:
#
# Carga del dataset 1
#
dataset_1 = pd.read_csv("/tmp/dataset_1.csv")
#
# Carga del dataset 2
#
dataset_2 = pd.read_csv("/tmp/dataset_2.csv")
#
# Concat con valores por defecto
#
datasets_12 = pd.concat(
objs=[
dataset_1,
dataset_2,
],
#
# axis= 0/index, 1/columns
#
axis=0,
#
# join={'inner', 'outer'}
#
join="outer",
#
# ignore_index=bool
#
ignore_index=False,
#
# sort=bool
# Ordena el otro eje si el join es 'outer'.
# Se ignora cuando es 'inner'
#
sort=False,
)
#
# Observe que hay numeros de fila repetidos (index)
# ignore_index=False
#
datasets_12
[6]:
name location
0 Omar Y. Fletcher 6833 Mollis. Rd.
1 Buffy W. Vincent P.O. Box 345, 8390 Ante Avenue
2 Mira N. Franklin P.O. Box 445, 323 Cursus Rd.
3 Ferris Q. Le Ap #791-3809 Eu Street
4 Michael I. Gray 6715 Diam. Rd.
5 Alan T. Mullins 512-3640 Nisl Rd.
6 Morgan W. Zamora 416-6030 Vivamus Road
7 Lilah O. Morrison 3859 Mauris Ave
8 Chantale Z. Kelley 3433 Arcu. Rd.
9 Randall Q. Mcclure Ap #584-7470 Nibh. Ave
0 Baker C. Hurst 249-6250 Velit. Rd.
1 Bevis W. Molina P.O. Box 935, 1521 At, St.
2 Martina B. Schroeder 689-7600 Mi St.
3 Kylie G. Bailey 1430 Diam. Road
4 Steel K. Glover 757-681 Et, Av.
5 Lucas M. Suarez 699-9329 Magna Rd.
6 Anastasia Q. Mccray P.O. Box 780, 4487 Lobortis, St.
7 Germaine Q. Henson 589-4921 Duis Ave
8 Wilma U. Mcfadden 6917 Dictum Rd.
9 Merritt Q. Martinez P.O. Box 469, 7833 Euismod Av.
[7]:
#
# Se ingnora el índice
#
datasets_12 = pd.concat(
objs=[
dataset_1,
dataset_2,
],
ignore_index=True,
)
datasets_12
[7]:
name location
0 Omar Y. Fletcher 6833 Mollis. Rd.
1 Buffy W. Vincent P.O. Box 345, 8390 Ante Avenue
2 Mira N. Franklin P.O. Box 445, 323 Cursus Rd.
3 Ferris Q. Le Ap #791-3809 Eu Street
4 Michael I. Gray 6715 Diam. Rd.
5 Alan T. Mullins 512-3640 Nisl Rd.
6 Morgan W. Zamora 416-6030 Vivamus Road
7 Lilah O. Morrison 3859 Mauris Ave
8 Chantale Z. Kelley 3433 Arcu. Rd.
9 Randall Q. Mcclure Ap #584-7470 Nibh. Ave
10 Baker C. Hurst 249-6250 Velit. Rd.
11 Bevis W. Molina P.O. Box 935, 1521 At, St.
12 Martina B. Schroeder 689-7600 Mi St.
13 Kylie G. Bailey 1430 Diam. Road
14 Steel K. Glover 757-681 Et, Av.
15 Lucas M. Suarez 699-9329 Magna Rd.
16 Anastasia Q. Mccray P.O. Box 780, 4487 Lobortis, St.
17 Germaine Q. Henson 589-4921 Duis Ave
18 Wilma U. Mcfadden 6917 Dictum Rd.
19 Merritt Q. Martinez P.O. Box 469, 7833 Euismod Av.
[8]:
bonus = pd.read_csv("/tmp/bonus.csv")
#
# Se requiere que los datasets tengan los mismos
# indices en las filas.
#
dataset_full = pd.concat(
[
datasets_12,
bonus,
],
axis=1,
)
dataset_full
[8]:
name location bonus
0 Omar Y. Fletcher 6833 Mollis. Rd. 279
1 Buffy W. Vincent P.O. Box 345, 8390 Ante Avenue 138
2 Mira N. Franklin P.O. Box 445, 323 Cursus Rd. 227
3 Ferris Q. Le Ap #791-3809 Eu Street 160
4 Michael I. Gray 6715 Diam. Rd. 267
5 Alan T. Mullins 512-3640 Nisl Rd. 231
6 Morgan W. Zamora 416-6030 Vivamus Road 169
7 Lilah O. Morrison 3859 Mauris Ave 263
8 Chantale Z. Kelley 3433 Arcu. Rd. 233
9 Randall Q. Mcclure Ap #584-7470 Nibh. Ave 292
10 Baker C. Hurst 249-6250 Velit. Rd. 208
11 Bevis W. Molina P.O. Box 935, 1521 At, St. 247
12 Martina B. Schroeder 689-7600 Mi St. 240
13 Kylie G. Bailey 1430 Diam. Road 161
14 Steel K. Glover 757-681 Et, Av. 248
15 Lucas M. Suarez 699-9329 Magna Rd. 216
16 Anastasia Q. Mccray P.O. Box 780, 4487 Lobortis, St. 291
17 Germaine Q. Henson 589-4921 Duis Ave 215
18 Wilma U. Mcfadden 6917 Dictum Rd. 463
19 Merritt Q. Martinez P.O. Box 469, 7833 Euismod Av. 790
Concatenación usando un campo clave
Creación del primer dataframe.
[9]:
%%writefile /tmp/dataset_1.csv
clientId,name,location
10,Omar Y. Fletcher,6833 Mollis. Rd.
11,Buffy W. Vincent,"P.O. Box 345, 8390 Ante Avenue"
12,Mira N. Franklin,"P.O. Box 445, 323 Cursus Rd."
13,Ferris Q. Le,Ap #791-3809 Eu Street
14,Michael I. Gray,6715 Diam. Rd.
15,Alan T. Mullins,512-3640 Nisl Rd.
16,Morgan W. Zamora,416-6030 Vivamus Road
17,Lilah O. Morrison,3859 Mauris Ave
18,Chantale Z. Kelley,3433 Arcu. Rd.
19,Randall Q. Mcclure,Ap #584-7470 Nibh. Ave
Overwriting /tmp/dataset_1.csv
Creación del segundo dataframe.
[10]:
%%writefile /tmp/dataset_2.csv
clientId,name,location
20,Baker C. Hurst,249-6250 Velit. Rd.
21,Bevis W. Molina,"P.O. Box 935, 1521 At, St."
22,Martina B. Schroeder,689-7600 Mi St.
23,Kylie G. Bailey,1430 Diam. Road
24,Steel K. Glover,"757-681 Et, Av."
25,Lucas M. Suarez,699-9329 Magna Rd.
26,Anastasia Q. Mccray,"P.O. Box 780, 4487 Lobortis, St."
27,Germaine Q. Henson,589-4921 Duis Ave
28,Wilma U. Mcfadden,6917 Dictum Rd.
29,Merritt Q. Martinez,"P.O. Box 469, 7833 Euismod Av."
Overwriting /tmp/dataset_2.csv
Creación del tercer dataframe.
Note que el campo clientId está en un orden diferente al de los archivos.
[11]:
%%writefile /tmp/bonus.csv
clientId, bonus
28, 463
29, 790
11, 138
12, 227
15, 231
24, 248
25, 216
26, 291
10, 279
13, 160
14, 267
27, 215
16, 169
17, 263
18, 233
19, 292
20, 208
21, 247
22, 240
23, 161
Overwriting /tmp/bonus.csv
Carga y concatenación de los dos primeros dataframes.
[12]:
dataset_1 = pd.read_csv("/tmp/dataset_1.csv")
dataset_2 = pd.read_csv("/tmp/dataset_2.csv")
datasets_12 = pd.concat(
[
dataset_1,
dataset_2,
],
ignore_index=True,
)
#
# Usa la columna clientId como índice de los
# registros
#
datasets_12.set_index("clientId", inplace=True)
datasets_12
[12]:
name location
clientId
10 Omar Y. Fletcher 6833 Mollis. Rd.
11 Buffy W. Vincent P.O. Box 345, 8390 Ante Avenue
12 Mira N. Franklin P.O. Box 445, 323 Cursus Rd.
13 Ferris Q. Le Ap #791-3809 Eu Street
14 Michael I. Gray 6715 Diam. Rd.
15 Alan T. Mullins 512-3640 Nisl Rd.
16 Morgan W. Zamora 416-6030 Vivamus Road
17 Lilah O. Morrison 3859 Mauris Ave
18 Chantale Z. Kelley 3433 Arcu. Rd.
19 Randall Q. Mcclure Ap #584-7470 Nibh. Ave
20 Baker C. Hurst 249-6250 Velit. Rd.
21 Bevis W. Molina P.O. Box 935, 1521 At, St.
22 Martina B. Schroeder 689-7600 Mi St.
23 Kylie G. Bailey 1430 Diam. Road
24 Steel K. Glover 757-681 Et, Av.
25 Lucas M. Suarez 699-9329 Magna Rd.
26 Anastasia Q. Mccray P.O. Box 780, 4487 Lobortis, St.
27 Germaine Q. Henson 589-4921 Duis Ave
28 Wilma U. Mcfadden 6917 Dictum Rd.
29 Merritt Q. Martinez P.O. Box 469, 7833 Euismod Av.
Carga y concatenación del tercer dataframe.
[13]:
bonus = pd.read_csv("/tmp/bonus.csv")
bonus = bonus.set_index("clientId")
bonus
[13]:
bonus
clientId
28 463
29 790
11 138
12 227
15 231
24 248
25 216
26 291
10 279
13 160
14 267
27 215
16 169
17 263
18 233
19 292
20 208
21 247
22 240
23 161
[14]:
dataset_full = pd.concat(
[
datasets_12,
bonus,
],
axis=1,
)
dataset_full
[14]:
name location bonus
clientId
10 Omar Y. Fletcher 6833 Mollis. Rd. 279
11 Buffy W. Vincent P.O. Box 345, 8390 Ante Avenue 138
12 Mira N. Franklin P.O. Box 445, 323 Cursus Rd. 227
13 Ferris Q. Le Ap #791-3809 Eu Street 160
14 Michael I. Gray 6715 Diam. Rd. 267
15 Alan T. Mullins 512-3640 Nisl Rd. 231
16 Morgan W. Zamora 416-6030 Vivamus Road 169
17 Lilah O. Morrison 3859 Mauris Ave 263
18 Chantale Z. Kelley 3433 Arcu. Rd. 233
19 Randall Q. Mcclure Ap #584-7470 Nibh. Ave 292
20 Baker C. Hurst 249-6250 Velit. Rd. 208
21 Bevis W. Molina P.O. Box 935, 1521 At, St. 247
22 Martina B. Schroeder 689-7600 Mi St. 240
23 Kylie G. Bailey 1430 Diam. Road 161
24 Steel K. Glover 757-681 Et, Av. 248
25 Lucas M. Suarez 699-9329 Magna Rd. 216
26 Anastasia Q. Mccray P.O. Box 780, 4487 Lobortis, St. 291
27 Germaine Q. Henson 589-4921 Duis Ave 215
28 Wilma U. Mcfadden 6917 Dictum Rd. 463
29 Merritt Q. Martinez P.O. Box 469, 7833 Euismod Av. 790
[15]:
#
# Se convierte el clientId a una columna
#
dataset_full = dataset_full.reset_index()
dataset_full
[15]:
clientId name location bonus
0 10 Omar Y. Fletcher 6833 Mollis. Rd. 279
1 11 Buffy W. Vincent P.O. Box 345, 8390 Ante Avenue 138
2 12 Mira N. Franklin P.O. Box 445, 323 Cursus Rd. 227
3 13 Ferris Q. Le Ap #791-3809 Eu Street 160
4 14 Michael I. Gray 6715 Diam. Rd. 267
5 15 Alan T. Mullins 512-3640 Nisl Rd. 231
6 16 Morgan W. Zamora 416-6030 Vivamus Road 169
7 17 Lilah O. Morrison 3859 Mauris Ave 263
8 18 Chantale Z. Kelley 3433 Arcu. Rd. 233
9 19 Randall Q. Mcclure Ap #584-7470 Nibh. Ave 292
10 20 Baker C. Hurst 249-6250 Velit. Rd. 208
11 21 Bevis W. Molina P.O. Box 935, 1521 At, St. 247
12 22 Martina B. Schroeder 689-7600 Mi St. 240
13 23 Kylie G. Bailey 1430 Diam. Road 161
14 24 Steel K. Glover 757-681 Et, Av. 248
15 25 Lucas M. Suarez 699-9329 Magna Rd. 216
16 26 Anastasia Q. Mccray P.O. Box 780, 4487 Lobortis, St. 291
17 27 Germaine Q. Henson 589-4921 Duis Ave 215
18 28 Wilma U. Mcfadden 6917 Dictum Rd. 463
19 29 Merritt Q. Martinez P.O. Box 469, 7833 Euismod Av. 790
Append
[16]:
#
# Append permite pegar un dataframe debajo de
# otro haciendo coincidir las columnas
#
dataset_1 = pd.read_csv("/tmp/dataset_1.csv")
dataset_2 = pd.read_csv("/tmp/dataset_2.csv")
dataset_2 = dataset_2[["name", "clientId", "location"]]
dataset_1.append([dataset_2, bonus])
[16]:
clientId name location bonus
0 10.0 Omar Y. Fletcher 6833 Mollis. Rd. NaN
1 11.0 Buffy W. Vincent P.O. Box 345, 8390 Ante Avenue NaN
2 12.0 Mira N. Franklin P.O. Box 445, 323 Cursus Rd. NaN
3 13.0 Ferris Q. Le Ap #791-3809 Eu Street NaN
4 14.0 Michael I. Gray 6715 Diam. Rd. NaN
5 15.0 Alan T. Mullins 512-3640 Nisl Rd. NaN
6 16.0 Morgan W. Zamora 416-6030 Vivamus Road NaN
7 17.0 Lilah O. Morrison 3859 Mauris Ave NaN
8 18.0 Chantale Z. Kelley 3433 Arcu. Rd. NaN
9 19.0 Randall Q. Mcclure Ap #584-7470 Nibh. Ave NaN
0 20.0 Baker C. Hurst 249-6250 Velit. Rd. NaN
1 21.0 Bevis W. Molina P.O. Box 935, 1521 At, St. NaN
2 22.0 Martina B. Schroeder 689-7600 Mi St. NaN
3 23.0 Kylie G. Bailey 1430 Diam. Road NaN
4 24.0 Steel K. Glover 757-681 Et, Av. NaN
5 25.0 Lucas M. Suarez 699-9329 Magna Rd. NaN
6 26.0 Anastasia Q. Mccray P.O. Box 780, 4487 Lobortis, St. NaN
7 27.0 Germaine Q. Henson 589-4921 Duis Ave NaN
8 28.0 Wilma U. Mcfadden 6917 Dictum Rd. NaN
9 29.0 Merritt Q. Martinez P.O. Box 469, 7833 Euismod Av. NaN
28 NaN NaN NaN 463.0
29 NaN NaN NaN 790.0
11 NaN NaN NaN 138.0
12 NaN NaN NaN 227.0
15 NaN NaN NaN 231.0
24 NaN NaN NaN 248.0
25 NaN NaN NaN 216.0
26 NaN NaN NaN 291.0
10 NaN NaN NaN 279.0
13 NaN NaN NaN 160.0
14 NaN NaN NaN 267.0
27 NaN NaN NaN 215.0
16 NaN NaN NaN 169.0
17 NaN NaN NaN 263.0
18 NaN NaN NaN 233.0
19 NaN NaN NaN 292.0
20 NaN NaN NaN 208.0
21 NaN NaN NaN 247.0
22 NaN NaN NaN 240.0
23 NaN NaN NaN 161.0